
I recently published a paper more thoroughly explaining what I have been developing as a part of my PhD research at the Laboratory for Computer Graphics and Multimedia, Faculty of Computer and Information Science.
The paper describes an alternative deep architecture. Those of you who are involved in recent machine learning research probably know neural-network-based deep architectures, which recently gained a lot of attention from general public due to their results in a variety of fields. However, they are not perfect (at least I think so … 🙂 ). To put it in a simple description, these networks lack transparence. We know how they work, but cannot see what they learn and thus often use them as black boxes (provide input, get output, don’t care about the process). We propose a different kind of deep architecture based on compositionality (large complex things are built of small simple things).
We tested our model on music information retrieval tasks and are currently seeking problems in other scientific fields dealing with big data – please message me for suggestions or potential collaboration.
If you are interested, I welcome you to read our paper, (freely) available here: http://dx.doi.org/10.1371/journal.pone.0169411
For a quick overview, I attached the paper’s abstract below:
Robust Real-Time Music Transcription with a Compositional Hierarchical Model
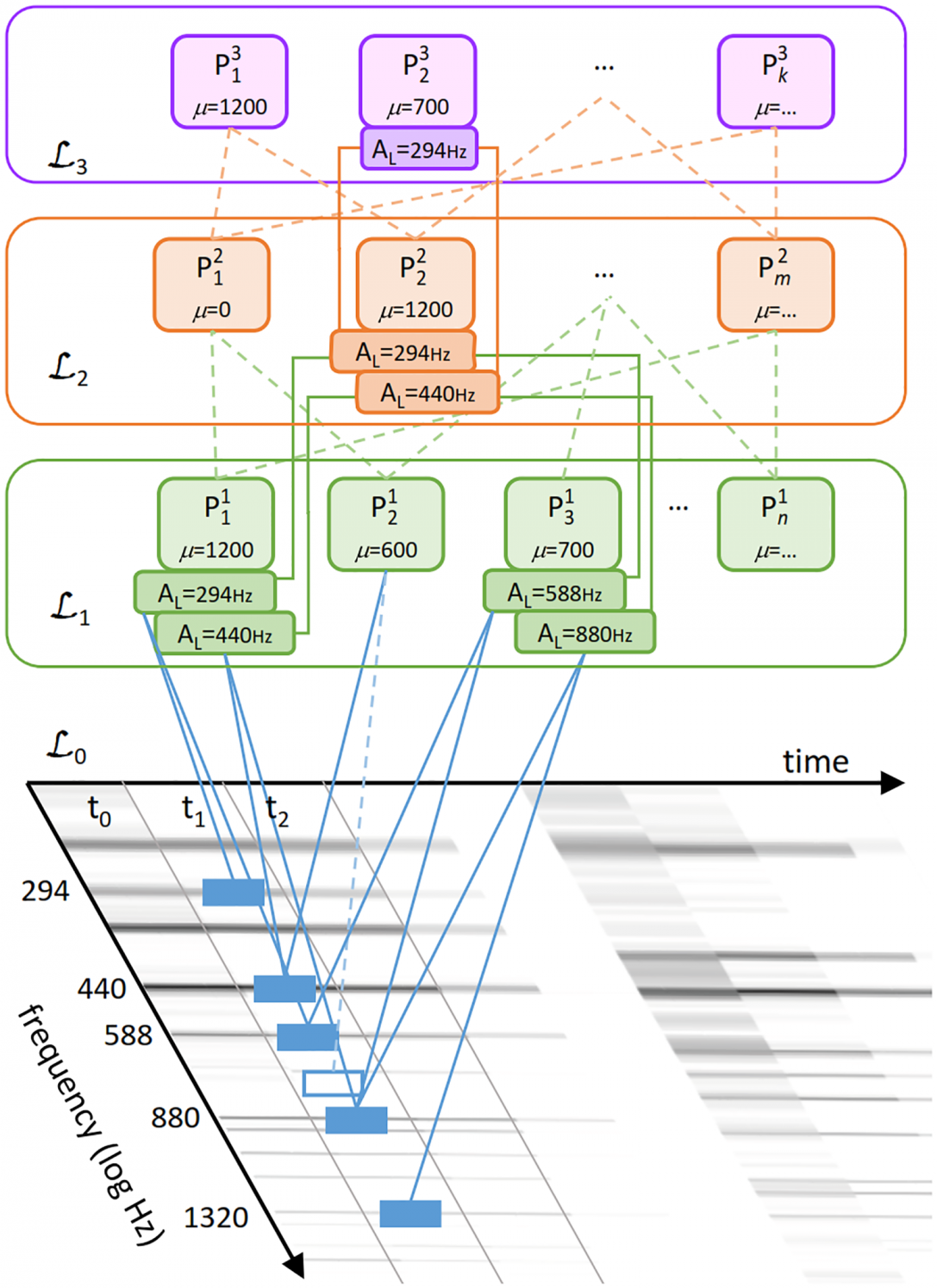
The paper presents a new compositional hierarchical model for robust music transcription. Its main features are unsupervised learning of a hierarchical representation of input data, transparency, which enables insights into the learned representation, as well as robustness and speed which make it suitable for real-world and real-time use.
The model consists of multiple layers, each composed of a number of parts. The hierarchical nature of the model corresponds well to hierarchical structures in music. The parts in lower layers correspond to low-level concepts (e.g. tone partials), while the parts in higher layers combine lower-level representations into more complex concepts (tones, chords). The layers are learned in an unsupervised manner from music signals. Parts in each layer are compositions of parts from previous layers based on statistical co-occurrences as the driving force of the learning process.
In the paper, we present the model’s structure and compare it to other hierarchical approaches in the field of music information retrieval. We evaluate the model’s performance for the multiple fundamental frequency estimation. Finally, we elaborate on extensions of the model towards other music information retrieval tasks.
Full paper is available here: http://dx.doi.org/10.1371/journal.pone.0169411
No Comments